开坑k8s,估计这个暑假结束时能够较为粗浅的学完…
k8s简介
k8s的全称是kubernetes,它是一款能够自动化部署,扩展,管理容器化应用的开源容器编排引擎
kubernetes取名于舵手的希腊文(κυβερνήτης),它于2014年在谷歌宣布成立.k8s的发展与设计很大程度上都借鉴了博格(Borg)系统,这是谷歌内部使用了近十几年的容器编排引擎
经过容器三大编排引擎的竞争,k8s击败了Mesos和Docker Swarm,赢得了全面的胜利,成为了容器编排引擎的事实上的标准
k8s概念
Cluster
Cluster是计算,存储和网络资源的集合,Kubernetes利用这些资源运行各种基于容器的应用.Cluster包括Master和Node
Master
Master是Cluster的大脑,它的主要职责是调度,即决定将应用放在哪里运行.Master运行Linux操作系统,可以是物理机或者虚拟机.为了实现高可用,可以运行多个Master
Node
Node的职责是运行容器应用.Node由Master管理,Node负责监控并汇报容器的状态,并根据Master的要求管理容器的生命周期.Node运行在Linux操作系统,可以是物理机或者是虚拟机
Pod
Pod是Kubernetes的最小工作单元.每个Pod包含一个或多个容器.Pod中的容器会作为一个整体被Master调度到一个Node上运行
Kubernetes引入Pod主要基于下面两个目的:
可管理性
有些容器天生就是需要紧密联系,一起工作.Pod提供了比容器更高层次的抽象,将它们封装到一个部署单元中.Kubernetes以Pod为最小单位进行调度,扩展,共享资源,管理生命周期
通信和资源共享
Pod中的所有容器使用同一个网络namespace,即相同的IP地址和Port空间.它们可以直接用localhost通信.同样的,这些容器可以共享存储,当Kubernetes挂载volume到Pod,本质上是将volume挂载到Pod中的每一个容器
大部分的Pod都运行单一的容器,只有少部分联系十分紧密以至于需要直接共享资源的容器才运行在同一个Pod中
Controller
Controller中定义了Pod的部署特性,比如有几个副本,在什么样的Node上运行等.Kubernetes提供了多种Controller,包括Deployment,ReplicaSet,DaemonSet,StatefuleSet,Job等
用户在创建应用时可以指定Controller,k8s的Controller Manager组件会管理各个Controller的生命周期
Deployment是最常用的Controller.Deployment可以管理Pod的多个副本,并确保Pod按照期望的状态运行
ReplicaSet实现了Pod的多副本管理.使用Deployment时会自动创建ReplicaSet,也就是说Deployment是通过ReplicaSet来管理Pod的多个副本,我们通常不需要直接使用 ReplicaSet
DaemonSet用于每个Node最多只运行一个Pod副本的场景.正如其名称所揭示的,DaemonSet通常用于运行daemon
StatefuleSet能够保证Pod的每个副本在整个生命周期中名称是不变的.而其他Controller不提供这个功能,当某个Pod发生故障需要删除并重新启动时,Pod的名称会发生变化.同时StatefuleSet会保证副本按照固定的顺序启动,更新或者删除
Job用于运行结束就删除的应用.而其他Controller中的Pod通常是长期持续运行
Service
每个Pod都有自己的IP,但这些IP位于Cluster内部,且随着Pod频繁的销毁和重启会发生变化.因此外界无法稳定的访问到Pod
Kubernetes Service定义了外界访问一组特定Pod的方式.Service有自己的IP和端口,Service为Pod提供了负载均衡
Kubernetes运行容器(Pod)与访问容器(Pod)这两项任务分别由Controller和Service执行
Namespace
Namespace用于多个用户或项目组使用同一个Kubernetes Cluster,将他们创建的Controller,Pod等资源分开
Namespace可以将一个物理的Cluster逻辑上划分成多个虚拟 Cluster,每个Cluster就是一个Namespace.不同Namespace里的资源是完全隔离的.
Kubernetes默认创建了两个Namespace:
- default:创建资源时如果不指定,将被放到这个Namespace中
- kube-system:Kubernetes自己创建的系统资源将放到这个Namespace中
k8s架构
k8s架构图:
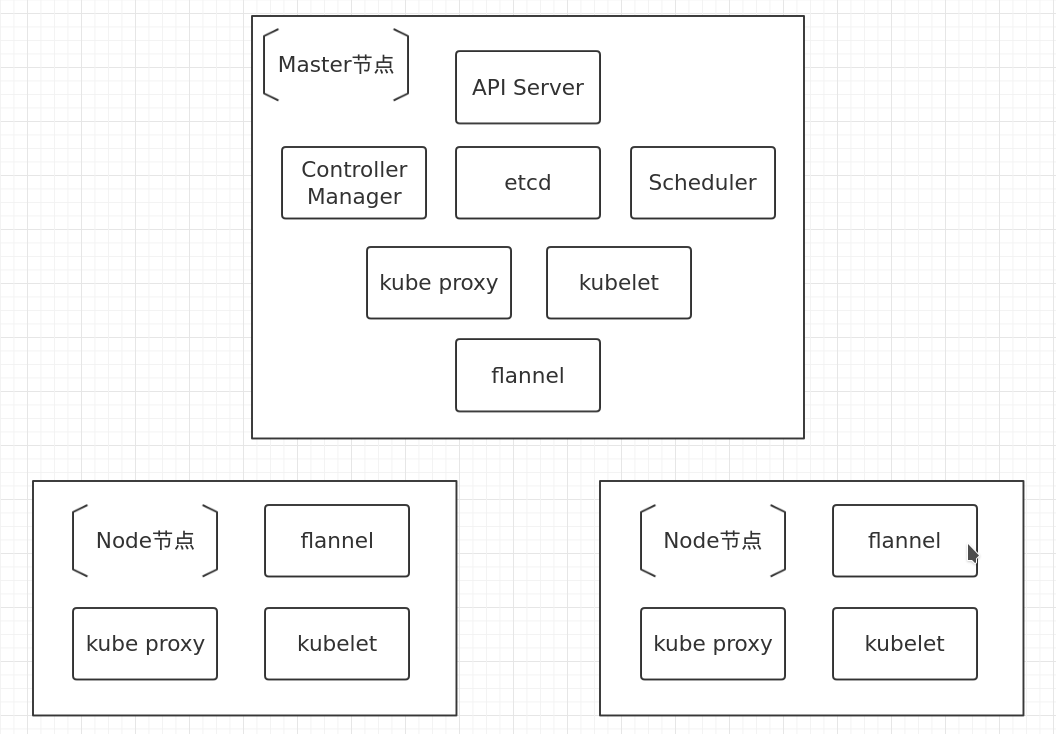
Kubernetes Cluster由Master和Node组成,节点上运行着若干Kubernetes服务
几乎所有的Kubernetes组件本身也运行在Pod里,可执行kubectl get pod --all-namespaces -o wide查看
kubelet是唯一没有以容器形式运行的Kubernetes组件,它一般通过Systemd运行
Master节点
Master是Kubernetes Cluster的大脑,运行着如下Daemon服务:kube-apiserver,kube-scheduler,kube-controller-manager,etcd和Pod网络(例如 flannel)
Master同时也是一个Node,因此也运行着kubelet和kube-proxy服务.k8s的默认策略不允许在Master上运行应用,可修改
API Server(kube-apiserver)
API Server提供HTTP/HTTPS RESTful API,即Kubernetes API.API Server是Kubernetes Cluster的前端接口,各种客户端工具(CLI或UI)以及Kubernetes其他组件可以通过它管理Cluster的各种资源
命令行工具kubectl就是通过API Server管理Cluster的
Scheduler(kube-scheduler)
Scheduler负责决定将Pod放在哪个Node上运行.Scheduler在调度时会充分考虑Cluster的拓扑结构,当前各个节点的负载,以及应用对高可用,性能,数据亲和性的需求
Controller Manager(kube-controller-manager)
Controller Manager负责管理Cluster各种资源,保证资源处于预期的状态.Controller Manager由多种controller 组成,包括replication controller,endpoints controller,namespace controller,serviceaccounts controller等
不同的controller管理不同的资源.例如replication controller管理Deployment,StatefulSet,DaemonSet的生命周期,namespace controller管理Namespace资源
etcd
etcd负责保存Kubernetes Cluster的配置信息和各种资源的状态信息.当数据发生变化时,etcd会快速地通知Kubernetes相关组件
Pod 网络
Pod要能够相互通信,Kubernetes Cluster必须部署Pod网络,flannel是其中一个可选方案
Node节点
Node是Pod运行的地方,Kubernetes支持Docker,rkt等容器Runtime.Node上运行的Kubernetes组件有kubelet,kube-proxy和Pod 网络(例如flannel)
kubelet
kubelet是Node的agent,当Scheduler确定在某个Node上运行Pod后,会将Pod的具体配置信息(image,volume等)发送给该节点的kubelet,kubelet根据这些信息创建和运行容器,并向Master报告运行状态
kube-proxy
Service逻辑上代表了后端的多个Pod,kube-proxy负责将Service接收到的请求转发至Pod
每个Node都会运行kube-proxy服务,它负责将访问service的TCP/UDP数据流转发到后端的容器.如果有多个副本,kube-proxy会实现负载均衡
Pod网络
Pod要能够相互通信,Kubernetes Cluster必须部署Pod网络,flannel是其中一个可选方案
k8s安装
k8s的安装过程比起其他的大型架构应该是相当简单了…但最致命的一点就是墙的问题-.-
实验环境:
host1:192.168.122.10:Master
host2:192.168.122.20:Node
host3:192.168.122.30:Node
安装Docker:
在每一个节点都安装Docker,官网推荐17.06之前的版本,不过我使用最新的18.05版本暂时没有出现问题
具体安装过程不再详述,推荐使用国内的镜像源.安装Docker后镜像也推荐使用国内加速,不然慢的一批
安装kubeadm,kubelet和kubectl:
在每个节点上都安装这些包,其中:
- kubeadm:用于初始化k8s cluster的工具
- kubelet:k8s cluster的组件,用于启动pod和container
kubectl:管理k8s cluster的工具
官网的安装源国内同样用不了…使用国内源:
1
2
3
4
5
6
7
8
9
10
11
12cat <<EOF > /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64/
enabled=1
gpgcheck=1
repo_gpgcheck=1
gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
EOF
setenforce 0
yum install -y kubelet kubeadm kubectl
systemctl enable kubelet && systemctl start kubelet注意RHEL/Centos用户需要做额外操作:
1
2
3
4
5cat <<EOF > /etc/sysctl.d/k8s.conf
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
EOF
sysctl --system
使用
kubeadm创建单Master的k8s cluster:kubeadm会自动从网上下载k8s cluster运行所需要的各个组件,然后配置并运行它们
这是国内用户最大的麻烦…不能翻墙的话,只能通过
-c参数通过配置文件手动指定下载的源1
]# kubeadm init --apiserver-advertise-address 192.168.122.10 --pod-network-cidr=10.244.0.0/16
- –apiserver-advertise-address指明用Master的哪个interface与Cluster的其他节点通信
- –pod-network-cidr指定Pod网络的范围.Kubernetes支持多种网络方案,而且不同网络方案对–pod-network-cidr有自己的要求,这里设置为10.244.0.0/16是因为我们将使用flannel网络方案,必须设置成这个CIDR
配置kubectl命令
建议使用非root用户运行kubectl命令.配置的方法实际上已经在
kubeadm init命令的输出写得明明白白了1
2
3mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config为了使用更便捷,可以添加kubectl的命令补全:
1
echo "source <(kubectl completion bash)" >> ~/.bashrc
安装Pod网络
要让k8s cluster工作,必须安装Pod网络,否则Pod之间无法通信
k8s支持多种网络方案,这里使用flannel:
1
kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/v0.10.0/Documentation/kube-flannel.yml
添加host2和host3
在host2和host3上执行如下命令:
1
kubeadm join --token d38a01.13653e584ccc1980 192.168.122.10:6443
token也写在了
kubeadm init命令的输出中,如果没记住的话,可使用kubeadm token list命令查看检查完成
通过
kubectl get nodes命令查看节点的状态通过
kubectl get pod --all-namespaces命令查看各组件的运行状态.各组件都在Pod中运行,首先需要在网上下载
k8s应用
运行应用
我们一般使用kubectl创建资源,并运行应用
以普通的web服务器nginx示例:
nginx.yml:
1 | apiVersion: extensions/v1beta1 |
使用apply创建资源,并运行nginx应用:
[kube@host1 ~]$ kubectl apply -f nginx.yml
依照nginx.yml文件,k8s将创建一个名为nginx-deployment的Deployment类型的Controller.那么,我们查看nginx-deployment干了什么
1 | [kube@host1 ~]$ kubectl describe deployments |
由Events的信息可以看出,nginx-deployment创建了nginx-deployment-6bd897fd69,它是ReplicaSet类型的Controller.继续查看nginx-deployment-6bd897fd69干了啥
1 | [kube@host1 ~]$ kubectl describe replicasets nginx-deployment-6bd897fd69 |
Controlled By表示此ReplicaSet由nginx-deployment创建;Events记录了3个副本Pod的创建.接着我们来看Pod
1 | [kube@host1 ~]$ kubectl describe pod nginx-deployment-6bd897fd69-5z5ln |
Controlled by指明该Pod由nginx-deployment-6bd897fd69创建;Events记录了该Pod的启动流程.Pod启动完毕即开始提供服务,也有可能添加Service资源负责映射IP
总结过程:
1 | kubectl |
用户通过
kubectl发送部署请求到API ServerAPI Server通知Controller Manager创建一个Deployment资源Deployment创建ReplicaSet资源ReplicaSet创建Pod资源Scheduler执行调度任务,将3个Pod分发到host2和host3
访问Pod
当创建Pod时,k8s默认会给予它一个随机IP,该IP是k8s的Pod网络分配的.flannel分配的IP以10.244开头:
1 | [kube@host1 ~]$ ip addr |
可以看到,host1,host2,host3的CIDR各不相同.在各节点分配Pod时,Pod的IP将按各节点的CIDR分配:
1 | [kube@host1 ~]$ kubectl get pod -o wide |
这些网络地址组成了一个巨大的k8s Cluster IP池,通过这些IP,能访问到各个节点的Pod:
1 | [root@host2 ~]# ping 10.244.2.25 |
然而,这些IP只能在k8s cluster的节点或容器内访问,外界无法访问,并且它们随时都可能改变.这时,就轮到Service资源发挥作用了
我们定义一个Service文件:
1 | apiVersion: v1 |
应用它:
1 | [kube@host1 ~]$ kubectl apply -f nginx_service.yml |
查看应用的nginx-svc:
1 | [kube@host1 ~]$ kubectl get service |
可以发现:
- nginx-svc的cluster-IP是10.110.60.75,通过这个固定的IP可以访问到后端的nginx Pod
- nginx-svc的cluster-IP映射到了每个Node的30000端口,通过这个端口可以从外界访问到Pod
通过describe可以查看Service与Pod的对应关系:
1 | [kube@host1 ~]$ kubectl describe service nginx-svc |
命令输出的Endpoints即3个nginx Pod的内部IP,Service的默认映射策略是概率相等的负载均衡策略:
1 | [kube@host1 ~]$ for i in $(seq 10);do curl 127.0.0.1:30000;done |
实际上,k8s的kube-dns组件还提供了DNS访问的功能.Cluster中的Pod可以通过格式为<SERVICE_NAME>.<NAMESPACE_NAME>的域名访问Service
1 | [kube@host1 ~]$ kubectl run busybox -it --rm --image=busybox /bin/sh |
由于该busybox Pod与nginx-svc同属于default命令空间,因此可以省略域名中的default
1 | / # wget nginx-svc:8080 |
存储管理
默认情况下数据都保存在容器中,这样一旦容器被销毁,数据也将随之消失.为了持久化数据存储,我们可以使用k8s volume
本质上,Kubernetes Volume是一个目录,这一点与Docker Volume类似.当Volume被mount到Pod,Pod中的所有容器都可以访问这个Volume,Kubernetes Volume也支持多种backend类型,包括empty Dir,hostPath,nfs,cephfs,rbd等等
emptyDir
emptyDir是最基础的Volume类型.正如其名字所示,一个emptyDir Volume是某个Node上的一个空目录
emptyDir Volume对于容器来说是持久的,对于Pod则不是.当Pod从节点删除时,Volume的内容也会被删除.但如果只是容器被销毁而Pod还在,则Volume不受影响
示例:生产者消费者模型
1 | apiVersion: v1 |
执行结果:
1 | [kube@host1 ~]$ kubectl apply -f producer_consumer.yml |
emptyDir的一个典型用途就是充当生产者消费者模型的中间人,生产者将处理的数据存放在emptyDir中,再让消费者使用.还可以使用tmpfs,效率极高
因为emptyDir是Docker Host文件系统里的目录,其效果相当于执行了docker run -v /producer_dir和docker run -v /consumer_dir,而两个容器都mount了同一个目录:
1 | [root@host3 ~]# docker inspect k8s_consumer_producer-consumer_default_46a82ff7-a1ef-11e8-8a11-525400909158_0 |
总结:
emptyDir是Host上创建的临时目录,其优点是能够方便地为Pod中的容器提供共享存储,不需要额外的配置.但它不具备持久性,如果Pod不存在了,emptyDir也就没有了.根据这个特性,emptyDir特别适合Pod中的容器需要临时共享存储空间的场景,比如前面的生产者消费者用例
hostPath Volume
hostPath Volume的作用是将Docker Host文件系统中已经存在的目录mount给Pod的容器.大部分应用都不会使用hostPath Volume,因为这实际上增加了Pod与节点的耦合,限制了Pod的使用.不过那些需要访问Kubernetes或Docker内部数据(配置文件和二进制库)的应用则需要使用hostPath
我们来查看一下kube-apiserver的配置文件:
1 | [kube@host1 ~]$ kubectl edit --namespace=kube-system pod kube-apiserver-host1 |
1 | volumeMounts: |
这里定义了三个hostPath volume:k8s,certs和pki,分别对应Host目录/etc/kubernetes,/etc/ssl/certs和/etc/pki
如果Pod被销毁了,hostPath对应的目录也还会被保留,从这点看,hostPath的持久性比emptyDir强.不过一旦Host崩溃,hostPath也就没法访问了
外部 Storage Provider
如果Kubernetes部署在诸如AWS,GCE,Azure等公有云上,可以直接使用云硬盘作为Volume
AWS Elastic Block Store示例:
1 | apiVersion: v1 |
Kubernetes Volume也可以使用主流的分布式存,比如Ceph,GlusterFS等
Cephfs示例:
1 | apiVersion: v1 |
相对于emptyDir和hostPath,这些Volume类型的最大特点就是不依赖Kubernetes.Volume的底层基础设施由独立的存储系统管理,与Kubernetes集群是分离的.数据被持久化后,即使整个Kubernetes崩溃也不会受损
PersistentVolume 和 PersistentVolumeClaim
PV和PVC主要是用来解耦合.用户若使用之前的数据持久化方案,则必须知道外置存储系统的相关配置信息,如Cephfs的monitor节点,keyring等信息.这些应该是系统管理员的责任而不是应用开发人员的.对此,k8s的解决方案是PV&PVC
PersistentVolume(PV)是外部存储系统中的一块存储空间,由管理员创建和维护.与Volume一样,PV具有持久性,生命周期独立于Pod
PersistentVolumeClaim(PVC)是对PV的申请(Claim).PVC通常由普通用户创建和维护.需要为Pod分配存储资源时,用户可以创建一个PVC,指明存储资源的容量大小和访问模式(比如只读)等信息,Kubernetes会查找并提供满足条件的PV
Kubernetes支持多种类型的PersistentVolume,如Cephfs,RBD,nfs等等
k8s应用配置文件示例
deployment
nginx:
1 | #当前配置文件版本 |
daemonset
Prometheus Node Exporter:
1 | apiVersion: extensions/v1beta1 |
Pod
livenessExample:用Liveness探测判断容器是否需要重启以实现自愈;用Readiness探测判断容器是否已经准备好对外提供服务
1 | apiVersion: v1 |
service
httpd:
1 | apiVersion: v1 |
job
echo一次性任务:
1 | apiVersion: batch/v1 |
定时运行任务:
1 | #注:k8s默认没有开启CronJob功能,需要在kube-apiserver的配置文件中修改 |
k8s命令
基础命令
1 | kubectl run NAME --image=image [--env="key=value"] [--port=port] [--replicas=replicas] [--dry-run=bool]:通过命令行直接创建一个资源 |
示例:
1 | kubectl run nginx-deployment --image=nginx:1.7.9 --replicas=2 |
部署命令
1 | kubectl rollout SUBCOMMAND [options]:管理一个资源的回滚 |
示例:
1 | kubectl rollout history deployment httpd |
集群管理命令
1 | kubectl taint NODE NAME KEY_1=VAL_1:TAINT_EFFECT_1 ... KEY_N=VAL_N:TAINT_EFFECT_N [options]:更新节点的策略 |
示例:
1 | kubectl taint node k8s-master node-role.kubernetes.io/master- |
排错与调试命令
1 | kubectl describe (-f FILENAME | TYPE [NAME_PREFIX | -l label] | TYPE/NAME):显示指定资源的细节 |
示例:
1 | kubectl describe pod |
高级命令
1 | 应用一个配置文件到资源中: |
示例:
1 | kubectl apply -f nginx.yml |
设置命令
1 | kubectl label [--overwrite] (-f FILENAME | TYPE NAME) KEY_1=VAL_1 ... KEY_N=VAL_N:更新一个资源的标记 |
示例:
1 | kubectl label node k8s-node1 disktype=ssd |
其他命令
1 | kubectl api-versions:打印支持的API的版本 |
参数细节
TYPE:pods|nodes|endpoints|events|namespaces|services|replicaSets|daemonSets|deployments